"In the end, there's way too much money in surveillance capitalism for any of these pathological stalkers to simply sit back and allow us to block them. They're on us today; they'll be on us tomorrow."

If you've ever installed a content-blocker (often known as a tracker-blocker) as a browser extension, you were probably pretty confident that it would block trackers. Like Domestos killing germs. One squirt, and it's goodbye bacteria. But blocking silent online trackers is a complex affair. Much more difficult than blocking adverts. And that means you're probably being watched by the bulk of Big Tech - even with the eminent extension uBlock Origin guarding your fort.
With an advert, the content itself is considered undesirable to the average website visitor, so all the providers of an adblocker need to do is establish which domains serve the ads, and then block them. Everyone's happy - among the site visitors, that is.
But silent trackers don't have that same inherent turn-off factor. Most of them are not running some excruciating graphical display designed to scream in our faces. Many are doing the exact opposite. They're aiming to enhance our experience in some way, by providing useful functions. And that means blocking trackers can bring disruption, rather than an improvement.
So with tracker-blockers, there has to be a balance between privacy and functionality. And with this in mind, an absolute army of trackers have used consumers' aversion to so-called "broken" page features, to loophole content-blocking, turning their data-grabbers into (supposedly) essential page dependencies. This creates a dilemma for the people producing the content-blockers and their block lists. Especially so, since some of the "essential" page dependencies are elements that only a minority of visitors would notice if they went missing.
For example, less than 1% of visitors will use a "Share to Twitter" button beneath an article. So for over 99% of visitors, all that button does is record their page visit and send the information to Twitter. Should that button be blocked, or allowed through the filter? It depends who you are. And even though fewer than 1% of people will use the Twitter share button, it can still be a very large number of people across the internet as a whole.
The above example is an obvious one, because the button is branded and its function is self-evident. But other tracking schemes exploiting the "page function dependency" narrative are more opaque. As a site visitor, you may not have a clue what they do, and they might use alternative domain branding to conceal their parentage. If you (or your content blocker) are looking for Yahoo/Verizon trackers, you may not be alerted by edgecastcdn.net. If you're looking for Facebook, you may not be alerted by fbcdn.net.
The "cdn" component in the domain names stands for "content delivery network", and running a content delivery network has become a classic resort for mega-trackers in modern times. Although the companies have to invest in a lot of bandwidth and server space to deliver images, scripts or whatever else to countless pages, because we broadly want the content or functionality that their CDNs distribute, their tracking mechanisms become much, much more difficult to avoid. Crucially, they get whitelisted by content-blockers, and that, for surveillance capitalists, can be well worth the investment.
Remote fonts are another route around the tracker-blocker. Remote fonts are a really important page component for site builders, because they allow full standardisation of how the web page's text is presented to all visitors - regardless of what they have installed on their own devices. This blog uses remote Google fonts, which doesn't really make any difference in privacy terms, because the blogging platform itself is Google-owned.
Without remote fonts, the visitor's own device will have to display the page using whichever fonts are available locally on their drive. If there isn't a match with what the site builder specified (say, the page was designed with Tahoma but the visitor doesn't have Tahoma locally installed), the page layout can be significantly affected, and can look unprofessional - reflecting badly on the website. Remote fonts solve this by serving the same fonts to everyone. They sort out a major design compatibility issue.
But the price to the visitor is that they can be tracked by the provider of the remote font(s). And statistically they probably will be, because by default, remote fonts will normally be allowed by a blocker - regardless of who supplies them. So Google Fonts allow Google to evade the default filtering on third party sites - even with a renowned blocker like uBlock Origin.
uBlock Origin is a vital tool for the privacy advocate, but if you just install it and assume the megatrackers aren't tracking you, you're making a big mistake. A huge number of trackers bypass uBlock's filters on the basis that they're supplying "essential" page content. Be it images, scripts, fonts, function buttons, or just the CAPTCHA you need to satisfy in order to see the page at all.
So, is there any point in using a content blocker? I mean, what's the use in blocking third-party intrusions from Google Analytics, Google Tag Manager, etc, if Google still picks up your IP when the font loads? Well, as a starting position I believe that blocking some trackers is better than blocking none. If only for the sake of driving the surveillance machine to provide more in return for the data it receives.
We shouldn't forget that the services many trackers have bankrolled in order to surmount content-blocking are helping keep websites' costs down, and are sometimes the difference between those sites remaining on the open web and disappearing behind paywalls. Whilst it's true that adblockers have helped push more content behind paywalls, tracker-blockers have, to an extent, done the opposite - decanting some site-running costs from the content creators to surveillance capitalists.
But from an obsessive privacy perspective, is there such a thing as a full-on, zero-tolerance, total block on third-party intrusion? Can we stop all the slippery, third-party trackers peeping at our activity if the content-blocker is allowing them to load as "dependencies"?
Yes, we can. And it's not at all difficult with uBlock Origin. The only thing to take into account is that this will disrupt the display of a huge number of pages. Some will be perfectly displayed. Some will be just about readable. Others will be blank. You just have to decide if completely blocking trackers is worth the disruption it causes.
I get round the problem by setting up a zero-tolerance, zero-trackers policy on one browser, and using that browser when I don't know where I'm heading. If I encounter a page where the disruption caused by content-blocking is too great, I can decide whether to ditch the visit altogether or load the URL into another browser with a less extreme policy.
If you think that might also work for you, here's the quick solution…
Install uBlock Origin as a browser extension.
Go into the uBlock Origin Dashboard and hit the My Filters tab.
Enter the two lines below into the filter pane…
||.^$third-party
*$script

You can see how it should look in the screen shot above.
Now simply hit Apply changes and it's job done.
[UPDATE: I've since found that even the above modification fails to block some shenanigans. Google CAPTCHAs, for example, were STILL sneaking through. I would therefore recommend adding ,important after each of the two lines, so…
||.^$third-party,important
*$script,important
This tightens the blocking further.
The two filter rules we added tell uBlock Origin to block ALL third-party page elements (line 1), and to block all scripts (line 2). You can get a less extreme version by only entering line 1. Scripting will still be blocked when it comes from a third party, but scripts from the first-party domain can still run. And you'll still be protected by uBlock's regular default rule-set. Try the options and see what happens.
Here's the difference it can make when both custom filters are added…

On the Birmingham Music Archive website there are a number of trackers. Not an unusual situation at all for a website in 2021. What you may find surprising is the number of them that uBlock Origin has allowed through the filter by default. In the uBlock report, the green domains are live on the page, the red domains are blocked, and the gold domains are partially blocked. We see that Facebook, Google, Twitter, Gravatar and Font Awesome have all managed to load a presence of some sort, and only Google Tag Manager has been unambiguously told to take a hike.
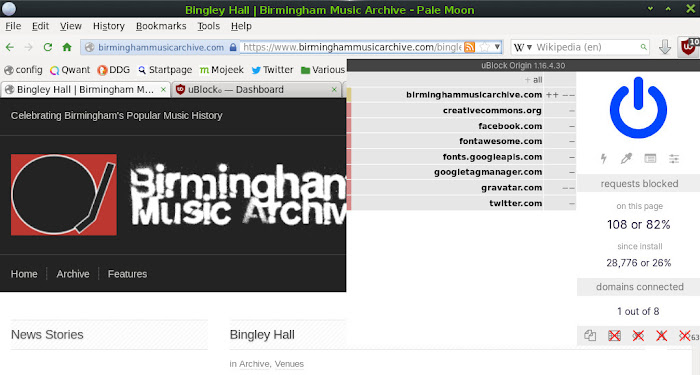
But with the two custom filters we added, nothing gets through except content from the website's home domain.
What's immediately noticeable after we've completely blocked third-party content and all scripts, is that the page still loads, and there's nothing really obvious that precludes us from reading it. We could therefore say that a glut of trackers on that page - allowed through on the pretext of "dependency" - were giving us, the visitor, very little, bordering on nothing, in return for their data grab.
If we were cynical, we might even believe that certain trackers were doing whitelisting deals with uBlock Origin. I don't know whether that is the case or not, but for that particular page, the necessity of those third-party trackers seems very tenuous indeed. The most renowned tracker-blocker on the scene is barely touching them, and whatever you want to argue, the official reason is that they're "essential components of the page".
In fairness, I did pick a page that survives very well without its third-party "dependencies". Many other pages will fall apart in terms of layout, and some will display nothing at all. This blog will still load, but you won't see any images, because they're on a separate (and therefore technically third-party) domain.
In the end, there's way too much money in surveillance capitalism for any of these pathological stalkers to simply sit back and allow us to block them. They're on us today; they'll be on us tomorrow. If they can't buy their way round the block, or destroy the technical means to implement blocking (as Google is attempting to do with its Manifest protocol changes), they'll try to redefine the way web pages are built so that they become a necessary part of the average page load process.
That, after all, is what big cybertech has always done. Insert itself between the provider and the consumer as a commission-earning middleman. Whether the commission is paid in cash or in data doesn't matter. Actually, that's not true. Data is preferable, because it's not instantly exhausted like money. It just keeps earning, over and over again. Not even oil can do that.